

What is Sharding?

The term “Shard” refers to “a small part of a larger whole.” Hence, Sharding refers to the process of dividing a more significant part into smaller portions.
Data Sharding is the process of splitting data tables into smaller chunks known as Shards. This is followed by distributing them across various data servers. The goal is to distribute data across a cluster of database nodes. This is done when the data cannot be accommodated on a single node.
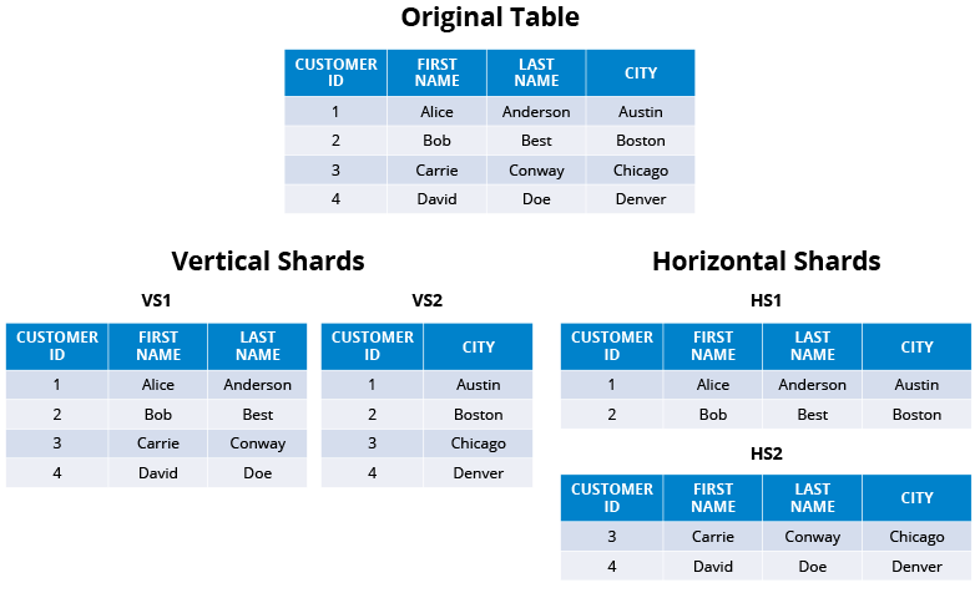
Sharding is commonly known as Horizontal Partitioning or Scaling-out. The critical variation between Horizontal and Vertical partitioning of a database arises from the conventional table-based view of databases. A database can be partitioned Vertically — storing different tables & columns across separate databases. This helps boost the power of a single machine or single server through a more powerful CPU, increased RAM, or higher storage capacity. It can also be split Horizontally — storing rows of the same table across multiple database nodes. This allows for near-limitless scalability to manage vast amounts of data and heavy workloads.
Sharding is a scale-out methodology where database tables are partitioned. Here, each partition is hosted on its own unique RDBMS server. For example, with MySQL, every node will operate as a distinct MySQL RDBMS, with a unique set of data partitions. Separating data thus allows applications to allocate queries to various servers in parallel and boost performance.
What is the need for Database Sharding?
Business applications that depend on RDBMS monolithic in nature like MySQL often face difficulties as they scale. With restricted CPU, storage capacity, and memory, query throughput & response times are unavoidably reduced. Vertical Scaling (scaling-up) has its own set of constraints for adding resources to support database activities. As a result, vertical Scaling often reaches a point of diminishing returns. In such situations, Database Sharding comes to the rescue.
By leveraging Database Sharding, you can boost the performance of your business applications. This approach also helps enhance the throughput even at scale. You can achieve a higher Compute power and capacity to handle incoming queries. Hence, it helps you establish index builds faster and process queries with quick response times.
From the beginning, it has been noticed that Business Databases usually expand in size over time. Hence, these typically have ever-increasing performance and capacity needs. Furthermore, the cost is always a driving factor for these tools. Therefore, firms must cut infrastructure costs while boosting performance and scalability to remain competitive in today’s challenging environment.
Initially, “Sharding” a single database across several separate servers may appear to hike costs, but with proper implementation, the financial benefits are enormous. Furthermore, it’s often seen that when the size and transaction volume of the database layer expands linearly, response times tend to rise logarithmically. In other words, a network of smaller, less expensive servers may be more cost-efficient in the long run than maintaining a single large server.
Sharding can improve overall cluster storage capacity, accelerate processing, and provide greater availability at a lower cost than Vertical Scaling.
Sharding Architecture and Types used in a SQL Database
1) Hashed/Algorithmic Sharding

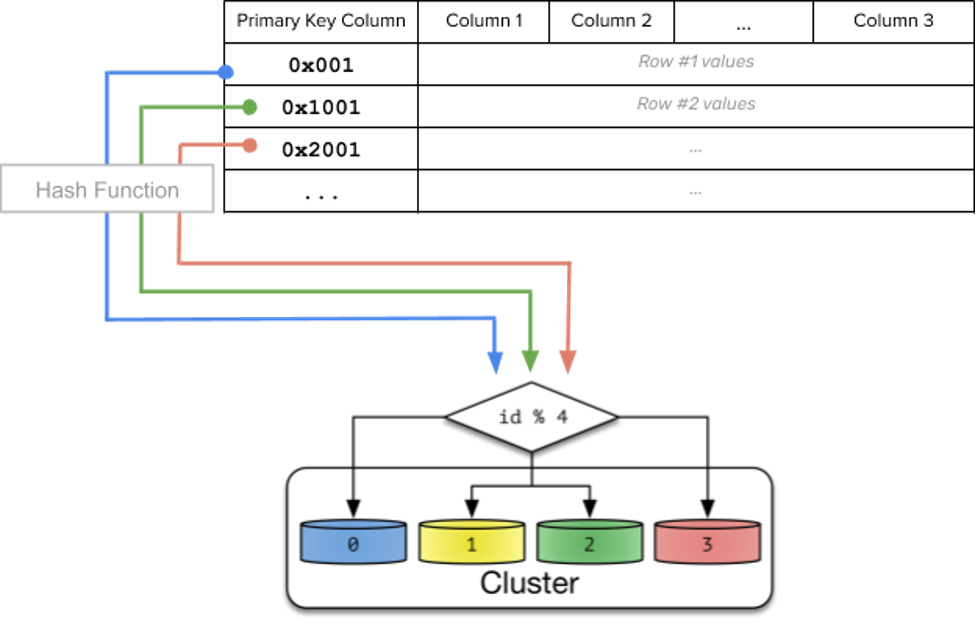
Hashed Sharding, also known as Algorithmic Sharding, takes a record as an input (Shard Key’s value) and executes a Hash-based function or Algorithm on it, resulting in an output or Hash Value. This output is then used to assign each record to the appropriate Shard, i.e., where the data should be stored.
The function can accept any subset of the record’s values as inputs. The modulus operator, along with the number of Shards, is perhaps the simplest example of a hash function:
Hash Value=ID % Number of Shards
Furthermore, with this method, data with similar Shard Keys is unlikely to be placed on the same Shard. As a result, this architecture is ideal for targeted data operations.
2) Range/Dynamic Sharding

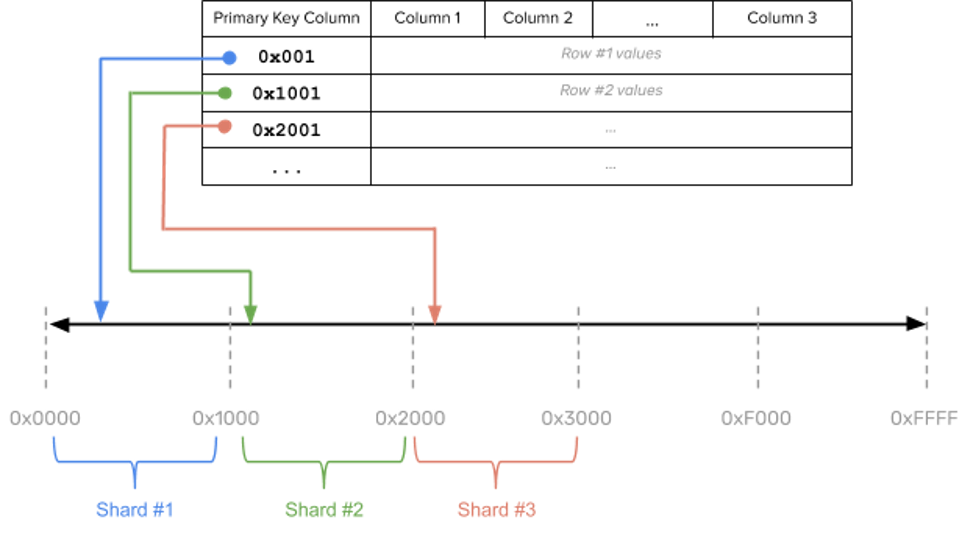
Ranged Sharding, also known as Dynamic Data Sharding, takes a field on a record as input and assigns that field to the appropriate Shard depending on a predetermined range. The attribute-based on which the range is decided is also known as the Shard Key. Naturally, the Shard key and ranges must be chosen carefully for Range-based Sharding to be effective. A poor Shard Key selection will result in uneven Shards, which will result in decreased performance. On the other hand, a good Shard Key will target queries to a minimum number of Shards.
Two essential attributes that make a Shard Key ideal and effective are Properly-distributed Frequency & High Cardinality. Here, Cardinality notes the number of possible values of that key. Whereas, Frequency relates to the distribution of the data along with the possible values. Both of these attributes should be considered while selecting a Shard Key. Without a proper Shard Key selection, data could end up unevenly distributed across Shards. Specific data could be queried more than the others, resulting in potential system bottlenecks in the Shards that receive a heavier workload.
The best way to deal with Irregular Shard sizes is to perform Automatic Shard Splitting and Merging. If the Shard gets too large or contains a frequently accessed row, splitting it into numerous Shards and rebalancing them across all available nodes can help improve performance. Conversely, the reverse technique can be leveraged when there are too many small Shards.
3) Entity/Relationship-Based Sharding
Entity-based Sharding, also known as Relationship-based Sharding, stores related entities in the same partition on a single physical shard. This helps provide additional capabilities within a single partition.
Specifically:
- Queries within a single physical shard are highly efficient.
- More robust consistency semantics can be obtained.
It is a frequently leveraged approach to Shard a Relational Database. The related data is often spread across multiple tables in an RDBMS (such as PostgreSQL, MySQL, or SQL Server).
Consider the following scenario: a shopping database with Customers and Invoicing Methods. Each customer has a set of payment methods that are tightly linked to that customer. Leveraging a single Shard to store related data points can help you lower broadcast operation requirements and boost performance.
4) Geography-Based Sharding
Geography-based Sharding, or Geosharding, retains related data collectively on a single Shard, but in this case, the data is associated by geography, i.e., the Shard Key contains geographic information, and the shards themselves are geo-located. Moreover, data is partitioned based on a user-specified column that maps Range Shards to specific regions and the nodes in those regions.
For example, consider a dataset in which each record has a “City” field. Here, we can increase overall performance while also lowering the latency by designing a Shard for each city or region and storing the appropriate data on that Shard. This is a fundamental example; however, there are various ways to assign your geoshards as well.
Conclusion
This blog talks about the different Sharding Architectures used in a distributed SQL Database in detail. It also gives a brief overview of Sharding.


Laila Azzahra is a professional writer and blogger that loves to write about technology, business, entertainment, science, and health.